Can LLMs write fast multi-GPU kernels? We built a benchmark to find out.
LLMs have gotten surprisingly good at writing GPU kernels[1][2][3], but almost all current
benchmarks measuring that progress are single-GPU. In production, communication is often the bottleneck: communication overhead can account for over 20% of inference latency[4], and that gap keeps widening as compute scales faster than interconnect bandwidth.
ParallelKernelBench (PKB) offers a benchmark and evaluation
framework for multi-GPU kernel generation and includes 87 problems from real
codebases where the task is replacing PyTorch + NCCL with a CUDA kernel that
moves data directly over NVLink. We tested frontier coding models such as GPT-5.5, Gemini 3 Pro, Opus 4.7, and
others. The evaluation revealed significant performance gaps across the board: under a third of problems were solved correctly,
and fewer than a quarter of those beat the naive baseline.
We'll cover why they fail, what the patterns look like, and a few cases where
models surprisingly produced kernels faster than anything publicly available, including one
for NVIDIA NeMo-RL's GRPO training loop, which has no prior optimized public
reference.
Why multi-GPU is different from single-GPU kernel generation
LLMs have made progress on GPU kernel generation, but that progress has mostly
been measured on a single GPU. Production AI workloads no longer fit that frame: they
span multiple GPUs, and performance is increasingly shaped by communication
rather than just local compute and memory. That shift makes multi-GPU kernel
generation a different problem in three ways:
The design space expands combinatorially. Practitioners
compose tensor, expert, data, context, and sequence parallelism to fit the
hardware, and each composition creates a different communication pattern.
The performance model changes. A single-GPU roofline is
built around compute and memory bandwidth. In multi-GPU code, the bottleneck
is often the interconnect.
Multi-GPU kernel generation introduces a critical new design choice:
how to move data between GPUs — through the copy engine, TMA, SM load/store,
or NVLS — and whether to fuse that movement with compute.
ParallelKernelBench
We built PKB to test whether models can move beyond pure torch.dist
and actually write production multi-GPU kernels. Each problem starts from a standard PyTorch
+ NCCL implementation and a description of the hardware topology. The model then
has to replace that reference with a CUDA kernel that communicates directly across
GPUs using symmetric memory.
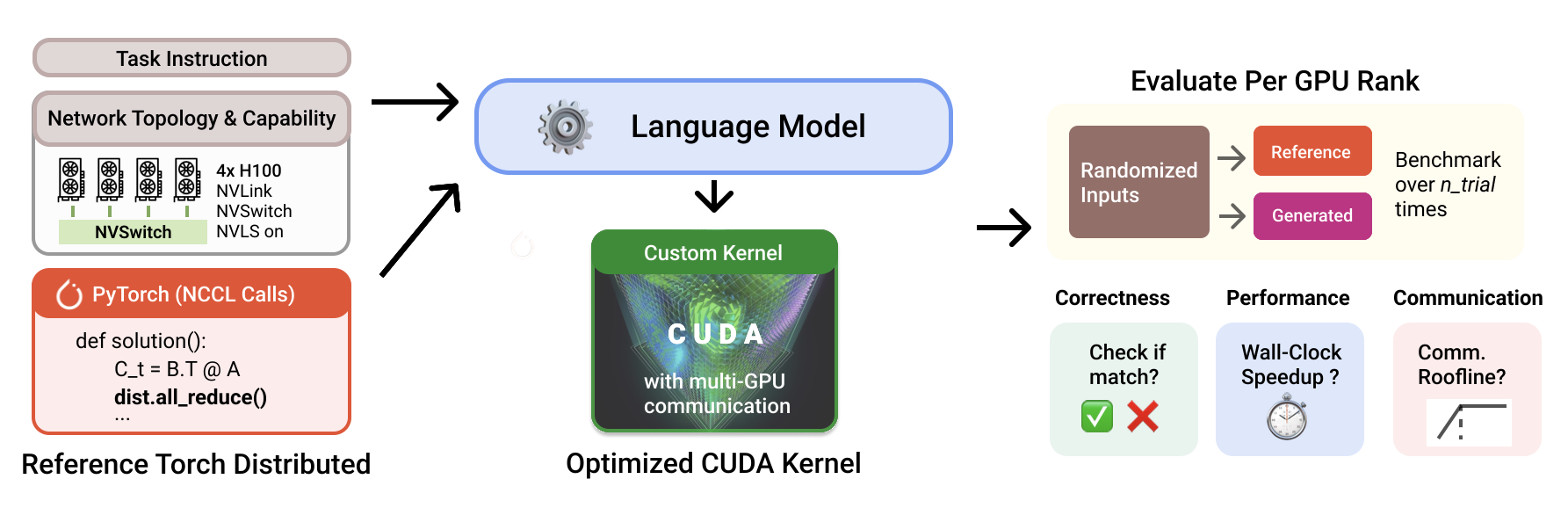
PKB evaluation pipeline. Each problem provides a task, hardware topology, and
PyTorch + NCCL reference; the model generates a custom CUDA kernel that is
evaluated for correctness, wall-clock speedup, and communication roofline.
To make sure the 87 problems cover the real space of production parallelism
types, we built them from a taxonomy of distributed workloads. First, we identified
the major ways models get sharded — tensor, context, data, expert, sequence, and
FSDP/ZeRO — along with the communication patterns each one creates. Then we chose
87 problems to cover that space taken from the codebases of systems like
Megatron-LM,
DeepSpeed,
DeepEP,
TensorRT-LLM,
NeMo-RL, as well as a long tail of
non-LLM workloads: GNN routing, distributed FFTs, Gaussian splatting, etc. Another benefit is that because PKB references are written in standard PyTorch + NCCL, the benchmark is not tied to any single, particular hardware generation. Instead, it is designed to naturally evolve alongside next-generation hardware architectures.
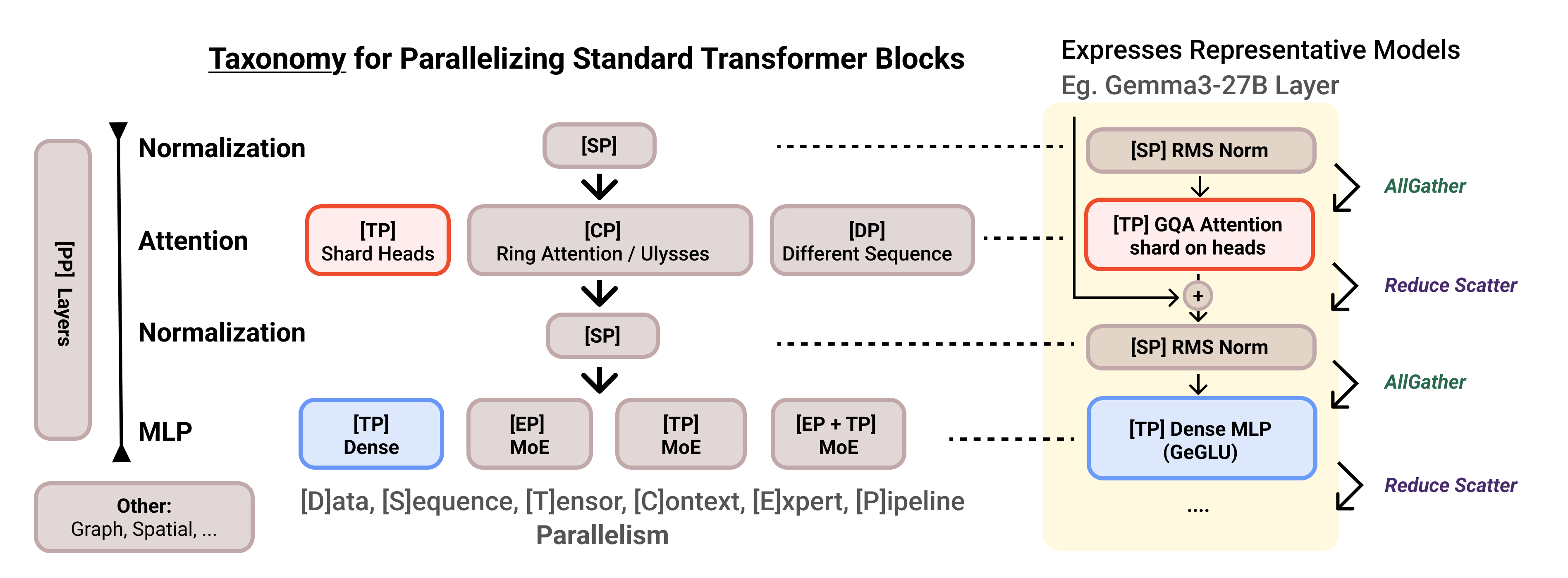
Taxonomy for parallelizing standard transformer blocks. Different sharding
strategies create distinct communication patterns across normalization,
attention, and MLP — illustrated here for a representative Gemma3-27B layer.
PKB problem coverage across parallelism types (left) and source codebases
(right), spanning RL post-training, LLM training, kernel libraries, vision
models, GNNs, and more.
Before evaluating models, we first checked whether the PyTorch + NCCL baselines
leave real headroom. A communication-aware roofline says yes: most PKB problems
are bottlenecked by NVLink, and the baselines run far below the hardware ceiling.
So the next question is simple: can models close that gap?
How frontier models do on PKB
Not well. In the zero-shot setting, the best model solves 28
of 87 problems, and only 22 of those solutions are faster than the PyTorch +
NCCL baseline. Sampling three attempts improves the best result to 36 correct
solutions and 27 faster-than-baseline solutions, but fast1@3 still
tops out at 31%.
Category
#
GPT-5.5
Claude Opus 4.7
Gemini 3 Pro
GLM-5.1
DeepSeek V4 Pro
pass @1→3
fast1 @1→3
pass @1→3
fast1 @1→3
pass @1→3
fast1 @1→3
pass @1→3
fast1 @1→3
pass @1→3
fast1 @1→3
Collective Primitive
8
3→5
3→4
4→5
3→4
6→6
2→2
2→3
2→3
0→0
0→0
Tensor Parallel
17
2→2
1→2
1→3
1→3
3→3
1→1
1→1
0→0
0→0
0→0
Sequence Parallel
2
1→1
1→1
0→0
0→0
0→0
0→0
0→0
0→0
0→0
0→0
Context Parallel
12
7→8
5→6
7→7
3→4
7→9
5→7
2→2
0→0
2→3
0→1
Pipeline Parallel
1
0→0
0→0
0→0
0→0
0→0
0→0
0→0
0→0
0→0
0→0
Data Parallel
9
1→2
1→2
1→1
1→1
0→1
0→0
0→0
0→0
0→0
0→0
Expert Parallel
11
3→3
2→3
2→6
0→1
3→4
0→1
0→0
0→0
0→0
0→0
FSDP / ZeRO
9
3→4
3→4
3→3
3→3
1→1
0→1
1→1
0→0
0→0
0→0
Vocab Parallel
4
2→2
1→1
1→2
1→2
2→2
2→2
0→0
0→0
0→0
0→0
Graph Parallel
6
2→4
2→3
0→2
0→2
1→1
1→1
0→0
0→0
0→0
0→0
Geometric / Spatial
5
3→3
3→3
1→2
0→0
0→1
0→1
0→0
0→0
0→0
0→0
Other
2
1→2
0→1
0→0
0→0
1→2
1→2
0→0
0→0
0→0
0→0
Total
87
28→36
22→27
20→31
12→20
24→30
12→19
6→7
2→3
2→3
0→1
Single-shot LLMs struggle on PKB.
pass@k reports correctness on the best of k attempts;
fast1@k counts solutions that are both correct and
outperform the PyTorch + NCCL baseline. Repeated sampling improves both metrics,
but fast1@3 still peaks at just 31% (GPT-5.5), suggesting
fundamental limitations beyond sampling noise.
The successes are concentrated in familiar patterns: collective primitives,
tensor-parallel GEMMs, and Ulysses-style context parallelism, which splits the sequence dimension across attention heads using all-to-all communication. These are the
parts of the multi-GPU stack most visible in open-source code, so models
likely have stronger priors for them.
The failures suggest a deeper issue than CUDA syntax. Weaker models often fail
to compile, but stronger reasoning models frequently produce kernels that
compile and return incorrect results. The hard part is reasoning about rank
coordination, data partitioning, and collective ordering.
Generated kernels also use a very narrow set of communication mechanisms.
Most rely on copy engines or SM load/store instructions, while more specialized
mechanisms such as TMA and NVLS are almost absent. In many cases, models do not
choose the mechanism needed for peak performance. We attribute this to a combination
of data scarcity and hardware complexity: newer primitives like TMA and NVLS require navigating intricate,
hardware-specific abstractions, such as asynchronous copy descriptors or newer NVLink topologies, where models lack strong priors.
That leaves a large gap
between “working” distributed kernels and genuinely optimized ones (a clear
target for future work!)
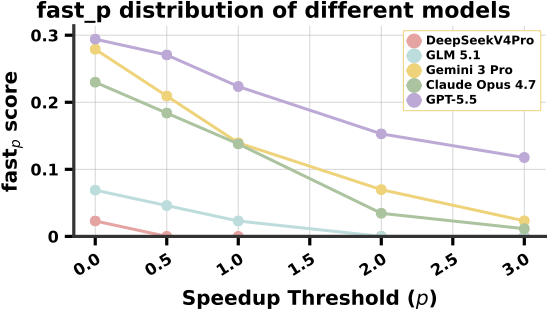
fastp score distribution across frontier models. Even the best
model (GPT-5.5) drops off quickly as the speedup threshold increases; at
p = 1.0, fast1 tops out around 31%.
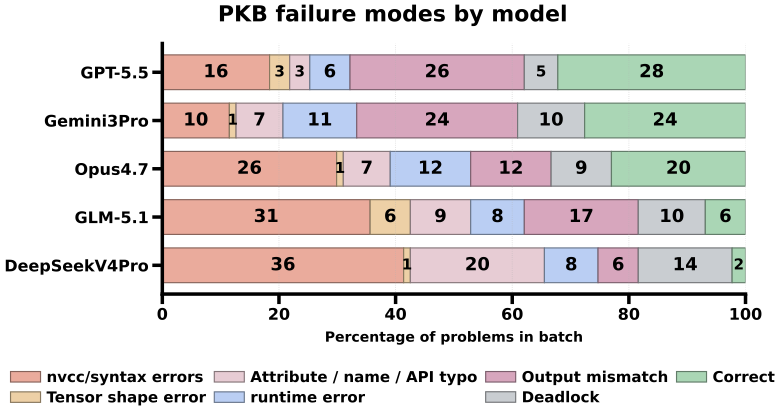
PKB failure modes by model. Weaker models fail mostly at compile time; stronger
reasoning models more often produce kernels that compile but return incorrect
results (output mismatch) or deadlock.
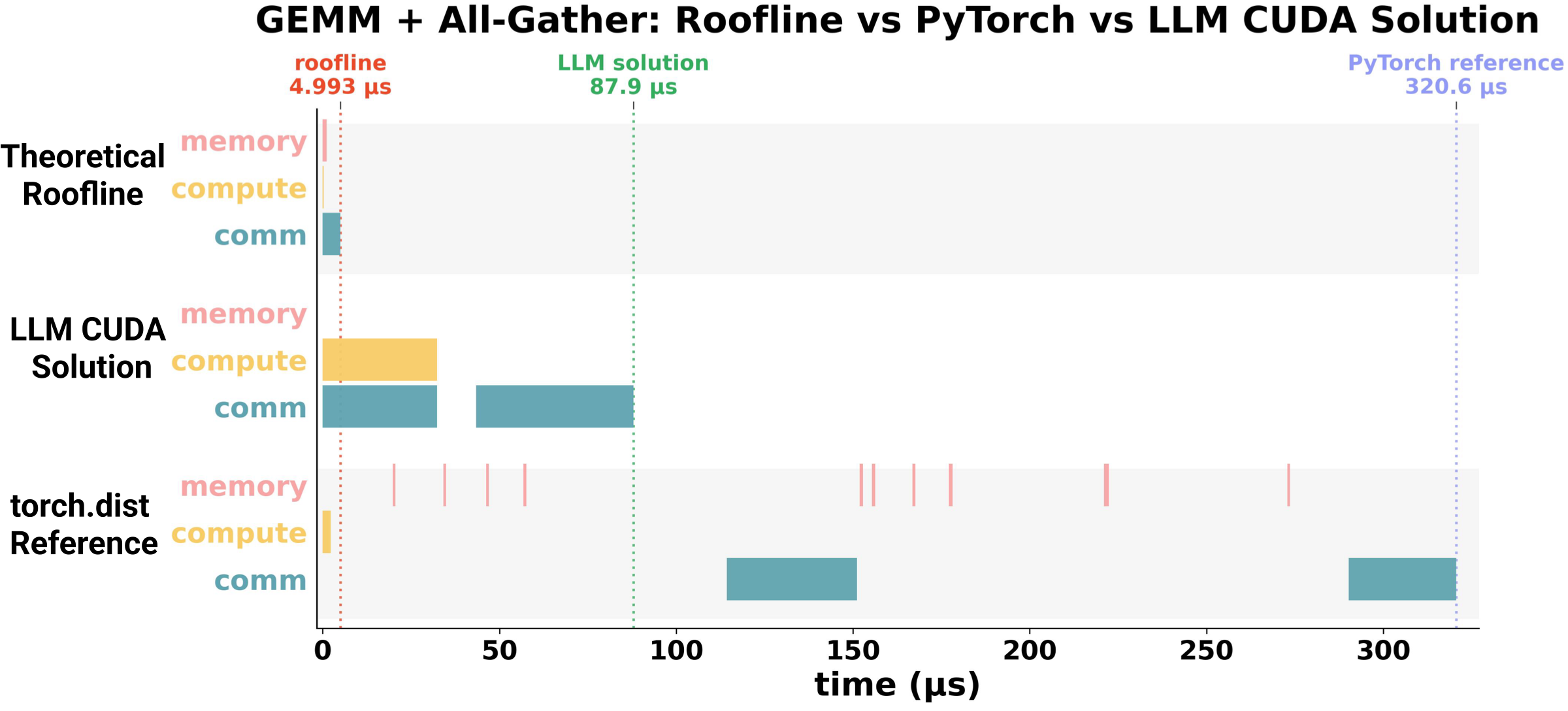
Profiler trace for GEMM + All-Gather: a generated CUDA kernel (87.9 μs)
overlaps compute and communication over NVLink, beating the PyTorch + NCCL
reference (320.6 μs) while still above the theoretical roofline
(4.99 μs).
The natural next step is to give the model the same feedback loop a human kernel
writer would use. We wrapped Gemini 3 Pro in an agentic harness with access to the
repository, a terminal, compiler output, correctness tests, speed measurements, and
its previous attempts. Instead of producing one kernel and stopping, the model could
compile, run the benchmark, inspect failures, and revise.
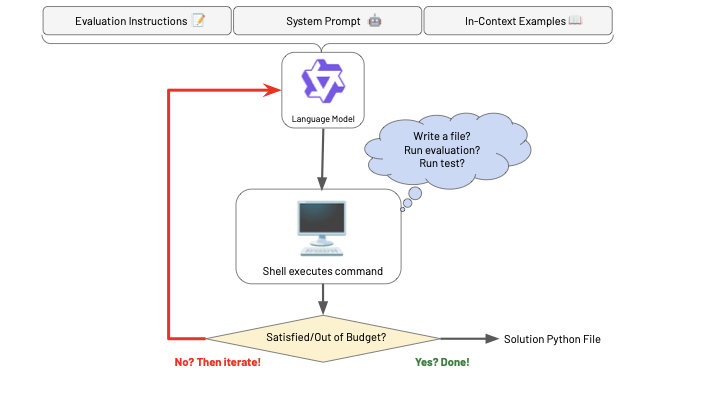
Agentic evaluation loop: the model writes files, runs correctness tests and
benchmarks, and iterates until the solution passes or the step budget is exhausted.
This helped, but the practical gains are modest. Gemini 3 Pro improved from 24
correct solutions in the single-shot setting to 35 out of 87, with 26 kernels
beating the PyTorch + NCCL baseline. The gains came from fixing syntax errors,
shape mistakes, and simple runtime bugs. After roughly 20 refinement steps,
performance plateaued. Feedback helps models debug distributed kernels, but the
remaining failures highlight a much bigger gap: an inability to reason about rank coordination,
communication ordering, and the optimal choice of GPU-to-GPU transfer mechanisms.
Net New Kernels
Example of replacing NCCL collectives with direct NVLink loads and stores:
the reference requires extra reshaping alongside NCCL collectives; the generated kernel fuses compute operations with direct peer memory reads.
Beyond speedups on standard collectives, single-shot generation occasionally
surfaces genuinely new high-performance kernels for workloads with no optimized
public reference. This capability offers a preview of the broader potential for AI-driven optimization; wins are not limited to Transformers, as models can do well on
state-space models, genomic pipelines, and multimodal RL loops — domains where
specialized kernels remain largely unoptimized compared to mainstream LLM stacks.
Below are three examples, each replacing NCCL collectives with
fused symmetric-memory kernels that move data directly over NVLink. Each was
verified for correctness over 4 H100 GPUs and 100 randomized runs; speed measurements follow
the benchmarking methodology in
ThunderKittens 2.0[5]
(bitwise-identical inputs, L2-aware input groups, 500 warmup iterations, and
100 back-to-back profiling iterations).
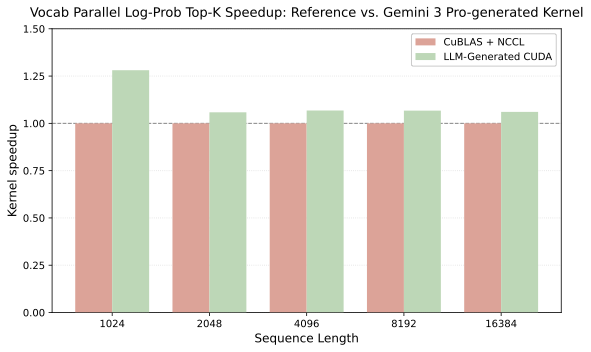
NeMo vocab-parallel log-prob with top-k/top-p filtering (Gemini 3 Pro)
A core step in NVIDIA NeMo-RL's GRPO training loop: compute vocabulary-sharded
log-probabilities under a top-k/top-p filtered distribution.
The PyTorch + NCCL baseline gathers the full vocabulary across ranks before
filtering; the generated kernel skips those collectives entirely, using symmetric
memory to permute shards inline while fusing log-softmax, token extraction, and
target gather into a single warp-shuffle reduction.
Speedup vs. PyTorch + NCCL across sequence length M ∈ {1024,
2048, 4096, 8192, 16384}. Config: 4 ranks, B = 1,
V = 32,000 (8,000 local vocab per rank), top-k = 10,
top-p = 0.9.
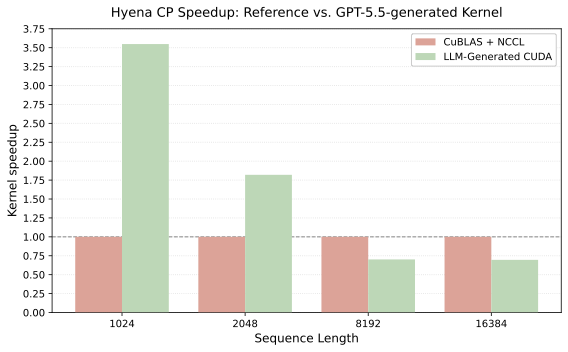
The context-parallel forward pass for the Hyena operator, where FFT convolution
needs sequence-global context. The reference alternates between sequence- and
channel-sharded layouts via repeated all_to_all calls; the generated
kernel packs inputs into one symmetric allocation and streams remote slices over
NVLink, computing gating and reindexing in a unified pass. Notably, performance degrades at longer sequence lengths.
Speedup vs. PyTorch + NCCL across local sequence length
l ∈ {1024, 2048, 8192, 16384} on 4 GPUs. Correctness
and speed measured over 100 trials.
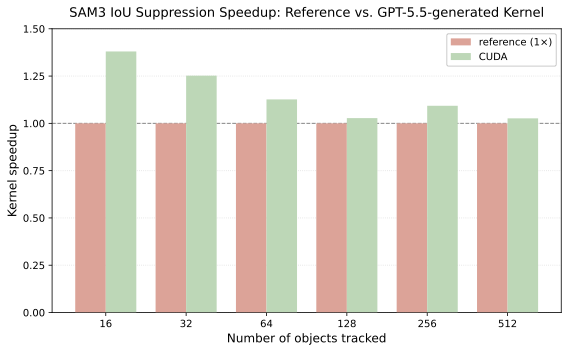
Cross-GPU duplicate suppression for SAM 3 video segmentation: after each frame,
ranks compare predicted regions via intersection-over-union and zero out
overlapping masks. The baseline uses variable-length all_gather
collectives plus a dense matmul; the generated solution collapses this into a
pipeline of symmetric-memory kernels that bitpack masks and compute pairwise
overlap with hardware popcount.
Speedup vs. PyTorch + NCCL across tracked objects
N ∈ {16, 32, 64, 128, 256, 512} at fixed mask resolution
256 × 256, IoU threshold = 0.7.
PKB is intentionally scoped to intra-node NVLink today. The natural extensions
are inter-node fabrics — RoCE, InfiniBand — where the device-side API landscape
is younger, and other accelerators and topologies like TPUs. We'd also like to
know whether higher-level abstractions help or hurt: PKB already accepts Triton
and ParallelKittens solutions, and emerging interfaces like NCCL GIN and NVSHMEM
are worth studying as targets. Expanding support to these paradigms will encourage further research into how AI agents navigate diverse programming models and hardware abstractions.
The broader goal is a concrete target for the harder problem behind all of this:
LLM systems that can autonomously optimize and manage large-scale distributed
infrastructure. For infrastructure custom-built for language model training and inference,
achieving this autonomy could ultimately bridge the gap to AI agents capable of handling their own
end-to-end research engineering.
We're releasing PKB as an open benchmark to push on that. If you
want to dig in or contribute problems — especially inter-node ones — we'd love to
hear from you. Feel free to email willychan2022@gmail.com or npaek@together.ai!
@misc{chan2026parallelkernelbench,
title = {ParallelKernelBench: Can LLMs Write Fast Multi-GPU Kernels?},
author = {Willy Chan and Nathan Paek and Simon Guo and Simran Arora and Daniel Y. Fu},
year = {2026},
url = {https://nathanjpaek.github.io/parallel-kernel-bench/}
}